爬虫抓取网站关键词的原理是什么?如何优化网站以提高抓取效率?
 游客
2025-07-13 08:57:01
3
游客
2025-07-13 08:57:01
3
在互联网信息爆炸的时代,网站关键词抓取成为了获取信息和进行数据分析的重要手段。爬虫技术的发展,使得这一过程变得更为高效和精确。本文将深入探讨爬虫如何抓取网站关键词,并提供一份详细的实操指南,帮助读者掌握这一技能。
一、理解爬虫与关键词抓取的关系
在开始之前,我们需要明确爬虫与关键词抓取之间的关系。爬虫是一种自动获取网页内容的程序,它能够按照既定的规则,自动访问互联网中的页面,抓取网页上的信息。而关键词抓取,则是在爬虫获取网页内容的基础上,进一步从网页文本中提取出关键词,这对于搜索引擎优化(SEO)、市场分析等场景至关重要。

二、爬虫抓取网站关键词的基本流程
1.网站选择与分析
在使用爬虫抓取关键词之前,首先要对目标网站进行分析。确定网站的结构、关键词分布情况以及内容更新频率,这有助于后续爬虫的定制化开发。
2.编写爬虫规则
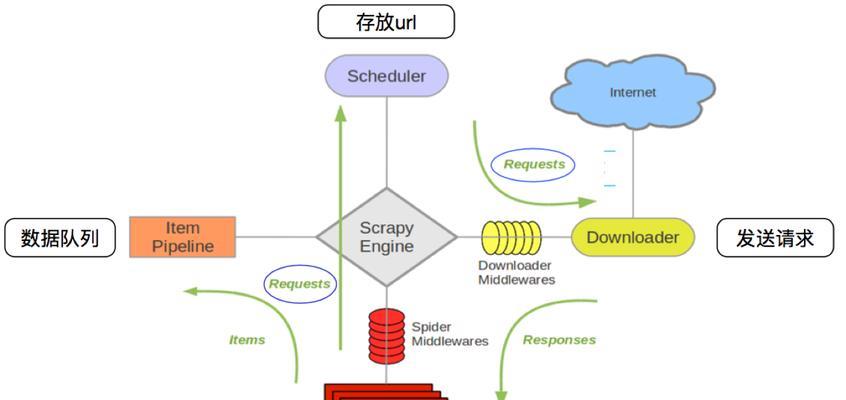
编写爬虫规则是实现高效抓取的关键步骤。常见的规则编写语言包括Python的Scrapy框架、JavaScript的Puppeteer等。规则编写中需要明确抓取哪些页面、哪些内容以及如何解析数据。
3.关键词提取技术
关键词提取一般有两种方式:基于规则的方法和基于统计的方法。基于规则的提取,如TF-IDF算法,通过分析词频与重要性来提取关键词;而基于统计的方法,则更多地依赖机器学习模型,如TextRank算法。
4.数据存储与管理
抓取到的数据需要被妥善存储和管理,以便后续分析。通常使用数据库来存储数据,如MySQL、MongoDB等,同时需要考虑数据清洗和格式化。
5.数据分析与应用
最后一步是数据分析和应用。对抓取到的关键词数据进行统计、分析,可以用来优化SEO策略、了解市场趋势或为产品改进提供数据支持。

三、爬虫抓取关键词的实操指南
1.环境准备
需要准备爬虫运行的环境,包括安装Python、Scrapy等必要的软件和库。
2.编写爬虫代码
以Python的Scrapy框架为例,创建一个Scrapy项目,编写爬虫类,定义要抓取的网站的URL、解析规则以及存储数据的格式。
```python
importscrapy
classKeywordSpider(scrapy.Spider):
name='keyword'
allowed_domains=['example.com']
start_urls=['http://example.com']
defparse(self,response):
提取网页中的关键词
keywords=response.css('div.content::text').getall()
存储数据
forkeywordinkeywords:
yield{'keyword':keyword}
```
3.数据提取与分析
在爬虫抓取到数据后,使用关键词提取算法对数据进行处理。利用jieba库进行中文分词:
```python
importjieba
content="这里是爬虫抓取到的网页文本内容。"
使用jieba进行中文分词
keywords=jieba.lcut(content)
print(keywords)
```
4.数据存储
将提取到的关键词存储到数据库中,比如使用SQLite进行简单的数据存储:
```python
importsqlite3
连接数据库
conn=sqlite3.connect('keywords.db')
cursor=conn.cursor()
创建表
cursor.execute('''CREATETABLEIFNOTEXISTSkeywords
(idINTEGERPRIMARYKEY,keywordTEXT)''')
插入数据
forkeywordinkeywords:
cursor.execute("INSERTINTOkeywords(keyword)VALUES(?)",(keyword,))
提交事务
conn.commit()
关闭连接
conn.close()
```
5.数据应用
利用提取的关键词数据进行分析,了解关键词的分布规律,为SEO或市场分析提供依据。

四、注意事项与常见问题
在进行爬虫抓取关键词的过程中,需要注意以下几点:
遵守目标网站的robots.txt协议,尊重网站爬取规则。
设置合理的爬取频率和时间,避免给目标网站服务器造成过大压力。
关注网站内容的更新频率,及时调整爬虫策略以保持数据的时效性。
避免使用过于激进的爬取方式,以免被目标网站的反爬虫机制封禁。
定期检查爬虫程序,确保数据抓取的准确性和完整性。
五、与展望
综上所述,爬虫抓取网站关键词是一个系统而细致的过程,涉及网站选择、规则编写、数据提取、存储和应用等多个环节。随着技术的不断发展,未来爬虫技术将更加智能化、个性化,并且能够在保证合法合规的前提下,为用户提供更为精准的数据服务。
通过本文的介绍,相信你已经对爬虫如何抓取网站关键词有了深入的理解。希望本文提供的实操指南能够帮助你在实际操作中更加得心应手。在遵循网络道德与法律法规的前提下,合理利用爬虫技术,将为你打开数据世界的大门。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 3561739510@qq.com 举报,一经查实,本站将立刻删除。
转载请注明来自火星seo,本文标题:《爬虫抓取网站关键词的原理是什么?如何优化网站以提高抓取效率?》
标签:


- 搜索
- 最新文章
- 热门文章
-
- 如何在淘宝联盟网站推广?推广效果不佳怎么办?
- HTML标签有哪些?它们的语法和含义是什么?
- HTML常用标签及其属性有哪些常见问题?如何正确使用它们?
- 博客登录网站怎么登录?遇到问题如何解决?
- HTML5移除了哪些元素?这些变化对网页设计有何影响?
- 如何提交网站地图给谷歌?步骤是什么?
- 网站如何推广方案?有哪些有效的推广策略?
- 博客网站怎么取名?如何选择一个吸引人的域名?
- 营销型网站怎么提高用户粘性?有效策略有哪些?
- 英山公众号推广网站的策略是什么?如何有效提高网站流量?
- 博客怎么搜索网站?如何快速找到所需内容?
- HTML标签属性有哪些?它们各自的作用是什么?
- 如何找国外渠道网站推广?有效策略和平台有哪些?
- 营销网站建设思路怎么写?如何打造有效的营销网站?
- 网站关键词排名怎么做?如何提升网站在搜索引擎中的关键词排名?
- 如何给网站安装百度地图?步骤是什么?
- 如何制作网站架构图站表标?步骤和要点是什么?
- 域名解析后网站怎么建设?解析后有哪些步骤需要跟进?
- 药网网站特色分析怎么写?如何深入理解其服务与功能?
- HTML前端框架有哪些?如何选择适合的框架?
- 热门tag
- 标签列表
